2020-06-02 09:50:04 0
AI視覺檢測機器系統
使用深度學習進行缺陷檢測
視覺檢查系統中檢測均勻背景對象(細線,緞紋等)中各種缺陷的技術。在制造業領域中,最近出現了“人力資源短缺”和“消費者需求多樣化”的趨勢,并且對自動視覺檢查系統的需求也在增加。然而,現有的檢查系統不能適應多種物體/缺陷類型。我們構建了深度學習模型,可以預先學習各種缺陷類型,從而構建了一個缺陷檢測系統,該系統使任何人都可以像人眼一樣自動執行檢查,而無需進行任何復雜的設置。
簡介
1.1背景
在制造領域,人力資源短缺和客戶需求的多樣化已經變得更加多樣化,并且對視覺檢查系統的自動化的需求也在增加。然而,現有的圖像傳感器僅使檢查過程自動化的一部分可行。原因如下:由于要制造的物體種類繁多,這種傳感器不能適應要檢查的物體的各種材料和形狀;除非具備豐富的專業知識,否則無法進行調整。為此,我們的目標是實現一種自動化的外觀檢查技術,該技術可以滿足適用于多種對象和缺陷類型的要求,并且任何人都可以輕松設置以實現檢查過程的自動化。
為了處理各種對象和缺陷類型,檢測缺陷的算法,突出顯示缺陷的輸入(照明/成像)技術以及適應對象輪廓的驅動技術都是必需的。在本文中,我們提出了一種用于檢測各種缺陷的缺陷檢測算法。
1.2使用深度學習進行預訓練類型缺陷檢測的建議
在深度學習方法帶來各種圖像分析結果的情況下,瓶頸在于圖像的收集。為了實際實現用于視覺檢查的深度學習,用于學習的圖像的收集將對現場工作人員構成巨大的負擔,從而使得在啟動產品線時難以確保足夠數量的學習圖像。在本文中,為解決該問題,我們提出了視覺檢查的自動化方法,其中應用了不需要為每個產品系列準備學習圖像的預訓練類型算法。
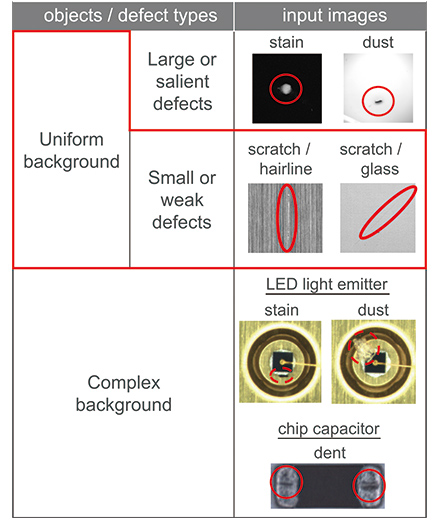
在目視檢查中,僅需檢測各種物體表面和缺陷類型中細微或細微差異的缺陷。如表1所示,可以對進行目視檢查的對象和缺陷類型進行分類。在分類檢查中,已經與現有圖像傳感器一起實際使用的檢查僅限于在統一背景下進行的顯著缺陷檢查。另一方面,本文提出的算法可以應用于均勻物體中的小缺陷或弱缺陷。因為一個統一的對象甚至在不同的產品系列中都顯示相似的特征,所以預訓練類型算法可以很好地工作。
2.系統概述
圖1是檢測處理的圖示。特征圖通過使用卷積神經網絡(CNN)的預訓練類型處理輸入圖像來表達可能的缺陷級別。此后,如此獲得的特征圖被二值化并提取為缺陷區域。
圖1檢驗系統概要
用于執行此類任務的深度學習研究案例通常基于包括對象檢測和語義分割的算法,以輸出處理結果1)。另一方面,本文提出的算法將特征圖設置為最終輸出。這是因為,對于實際的生產現場,對于每個產品線,關于產品缺陷是被歸類為缺陷產品還是被認為是合格產品的判斷是不同的,因此需要留出空間來設置閾值對于各行。實際的操作模型假設在生成特征圖(其中僅缺陷部分由所提出的算法突出顯示)并在圖像傳感器上進行簡單圖像處理的二值化或標記后,將該算法用作一系列檢查流程的一部分被申請;被應用; 因此,通過使用任何缺陷的位置和大小來執行驗收判斷。
3.生成缺陷檢測圖像的算法
在制造現場進行的缺陷檢查中,假設可能會在圖像中投影除缺陷以外的對象,并且在后處理階段可能需要對缺陷和其他對象進行分類。因此,應該安排成可以通過特征圖來標識位置和尺寸,在特征圖中可以對缺陷的可能程度成像。這種特征圖的準備包括以下兩個步驟(圖2)。
(1)假設檢查圖像中存在缺陷的可能性
(2)缺陷的估計位置的識別和成像
首先,對于步驟(1),將檢查圖像輸入到CNN中,并輸出圖像中可能存在缺陷的可能性,可能性為0到1。CNN的排列方式是,當圖案更接近缺陷時會輸出較高的值通過允許從許多缺陷圖像中預先學習,可以將這些元素包含在檢查圖像中。
接下來,對于步驟(2),確定從檢查圖像內的哪個位置導出在(1)中估計出的缺陷的概率。使用CNN,表示缺陷位置的信息包含在各個中間層的計算結果中2)并且,通過使用該信息,可以以檢查圖像像素為單位計算出對缺陷概率的貢獻度。最后,將每個像素的貢獻度乘以適當的放大倍率,從而創建特征圖。
圖3是特征圖的示例。在該圖中,隨著對缺陷概率的貢獻程度變高,顏色從藍色變為紅色。在檢查圖像中已知存在缺陷的部分顯示出較高的值。
4.學習圖像數據庫
為了使預學習型算法發揮全部性能,在開發時有必要構建一個大型的學習圖像數據庫(DB),該數據庫涵蓋制造現場生產的各種對象。但是,由于并不總是保存實際的產品線數據,并且這些數據通常可能是機密的,因此出于開發用途的目的收集數據并不容易。特別地,對于包含缺陷的圖像數據,還存在絕對數較小且優質產品的數據量不平衡的問題。
作為在可獲得可學習圖像的條件下構建數據庫的方法,將由計算機圖形學(CG)或生成對抗網絡(GAN)生成的偽圖像的方法用作學習圖像3),4),但很少在實際環境中顯示出有效性的情況。
因此,參照本文提出的算法的發展,實際創建并成像了包含缺陷類型,位置,大小,顏色,背景材料和光源設置的組合的對象的模式,從而構建了數據庫。圖4顯示了實際創建的組合模式的示例。

為了進行學習處理,在將圖像數量增加到800萬之后,使用了通過添加包括裁剪和添加噪聲的數據增強而獲得的圖像。DB的使用允許本文中提出的算法在制造現場處理各種對象和缺陷類型。
5.關于更高速度的考慮
通常,來自GPU的大量計算資源可用于實施深度學習。然而,對于在制造現場使用的圖像傳感器,由于諸如成本的問題,難以使用這種資源。因此,為了通過使用CPU的處理來提高高速性能,應將注意力集中在占用CNN處理時間的調用層上,從而針對圖像傳感器的硬件配置優化網絡結構和線纜安裝類型。根據輸入圖像的分辨率,這種布置實現了100 ms至600 ms的處理時間。
5.1優化網絡結構
盡管已經提出了幾種精密深度學習網絡,但是許多網絡都假定使用GPU,并且在大多數情況下,CPU中圖像傳感器的處理時間超過1000毫秒。本文提出的算法所采用的網絡是基于ResNet的5) 或開始6),這是用于一般對象識別任務的高精度和高速網絡的典型代表。此外,考慮到網絡的每一層都可以結合多種缺陷和背景圖案進行處理,因此結構上要優先考慮有效接收場的多功能性7),8)以及多樣化的高速結構 9) 具有特色,從而同時確保速度和精度。
5.2核近似
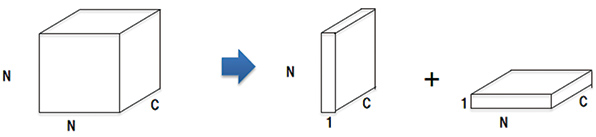
對于卷積運算,計算量與內核大小成比例地增加,因此,隨著內核大小變小,可以獲得更高的速度。另一方面,對于CNN,可以通過使用多個較小尺寸的卷積層來獲得等效于較大尺寸內核的卷積層的效果。10)。因此,我們將內核大小為NxNxC的卷積層劃分為包括1xNxC和Nx1xC兩個階段的兩個階段,從而縮短了總體計算時間。(圖5)
5.3并行操作指令的定點表示與利用
卷積是浮點數據行的乘積和運算。另一方面,對于圖像傳感器采用的CPU,可以使用并行執行多個數據的積和運算的單指令多數據(SIMD)。此外,SIMD還可以執行更多并行操作,作為表示數據的位數。參考卷積計算,通過實現輸入和輸出的8位定點表示,我們最多可以執行32個并行操作。
6.績效評估
我們將本文提出的算法應用于466個檢查圖像(對于優質產品為62個圖像;對于次品為404個圖像)以評估性能。用于比較的傳統方法的精度是通過針對每個對象優化流行的濾鏡(包括對比度增強和合并到圖像傳感器中的邊緣檢測)來優化的,從而提取缺陷區域。但是請注意,用于評估的圖像是成像環境和成像對象與本文采用的學習圖像不同的圖像。
表2顯示了性能評估的結果。類別“假陽性”表示從良好的產品圖像中檢測到錯誤,而“假陰性”表示未檢測到有缺陷的產品圖像。
表2績效評價結果
假陰性 假陽性
常規方法 3.2% 6.7%
擬議方法 0.9% 3.4% 該方法的假陽性和假陰性結果均顯示出較高的精度。另外,雖然常規方法需要選擇多個濾波器并針對每個對象調整幾個參數,但是使用所提出的方法需要調整的參數僅是特征圖的閾值,并且減少了調整的時間和精力。可以在生產現場進行工作。
該方法的假陽性和假陰性結果均顯示出較高的精度。另外,雖然常規方法需要選擇多個濾波器并針對每個對象調整幾個參數,但是使用所提出的方法需要調整的參數僅是特征圖的閾值,并且減少了調整的時間和精力。可以在生產現場進行工作。
圖6和7顯示了使用提出的算法提取缺陷區域的結果。圖的第一行示出了輸入圖像,第二行示出了使用結合在圖像傳感器中用于比較的常規方法從輸入圖像中提取缺陷區域的結果。最后的第三行顯示了使用提出的算法提取缺陷區域的結果。圖6示出了圖像包含與學習圖像相似的圖案的情況的結果,圖6(a)示出了緞面拋光的鋁被劃傷的物體。劃痕的寬度約為 4像素的分辨率足以滿足約4像素的要求。對比度低的輸入圖像的2000×2000,并且用常規方法進行的加工根本無法提取劃痕。另一方面,所提出算法的處理結果能夠提取劃痕區域,這是常規方法無法實現的,并且它忽略了在與劃痕相鄰的圖像區域上顯示出顯著顯著對比度的照明陰影。地區。圖6(b)示出了在其上具有污漬的塑料膜。該膜具有細的發際線,并且當用常規方法處理圖像時,源自發際線的噪聲在工作中很普遍。相反,所提算法的處理結果表明,缺陷區域可以更清晰地提取而不受細線的影響。所提算法的處理結果能夠提取出常規方法無法實現的劃痕區域,并且忽略了在與劃痕區域相鄰的圖像區域上顯示出更高顯著對比度的照明陰影。圖6(b)示出了在其上具有污漬的塑料膜。該膜具有細的發際線,并且當用常規方法處理圖像時,源自發際線的噪聲在工作中很普遍。相反,所提算法的處理結果表明,缺陷區域可以更清晰地提取而不受細線的影響。所提算法的處理結果能夠提取出常規方法無法實現的劃痕區域,并且忽略了在與劃痕區域相鄰的圖像區域上顯示出更高顯著對比度的照明陰影。圖6(b)示出了在其上具有污漬的塑料膜。該膜具有細的發際線,并且當用常規方法處理圖像時,源自發際線的噪聲在工作中很普遍。相反,所提算法的處理結果表明,缺陷區域可以更清晰地提取而不受細線的影響。它忽略了在與劃痕區域相鄰的圖像區域上顯示更高對比度的照明陰影。圖6(b)示出了在其上具有污漬的塑料膜。該膜具有細的發際線,并且當用常規方法處理圖像時,源自發際線的噪聲在工作中很普遍。相反,所提算法的處理結果表明,缺陷區域可以更清晰地提取而不受細線的影響。它忽略了在與劃痕區域相鄰的圖像區域上顯示更高對比度的照明陰影。圖6(b)示出了在其上具有污漬的塑料膜。該膜具有細的發際線,并且當用常規方法處理圖像時,源自發際線的噪聲在工作中很普遍。相反,所提算法的處理結果表明,缺陷區域可以更清晰地提取而不受細線的影響。
圖7顯示了與學習圖像有很多差異并且背景區域有信息時對象的輸出結果。圖7(a)示出了在鐵氧體芯上產生裂紋的圖像,并且在學習圖像中不存在包含該類型的信息的圖像。當用常規方法對該圖像進行處理時,盡管可以提取裂紋區域,但也可以提取鐵氧體磁心的形狀和源自表面粗糙度的邊緣。另一方面,該算法的處理結果表明,只有裂紋區域作為缺陷區域輸出。圖7(b)示出了圖像,其中木制智能手機蓋上存在灰塵。學習圖像不包括木制物體的圖像,并且不存在其中包括灰塵作為缺陷的圖案,因為這種圖案不是當前開發中的目標。當用常規方法加工該物體時,不僅灰塵,而且木紋部分也以相似的強度被提取。另一方面,使用提出的算法進行處理后發現,盡管沒有學習木材圖案和灰塵,但灰塵可能會作為缺陷而輸出,而忽略了木材圖案。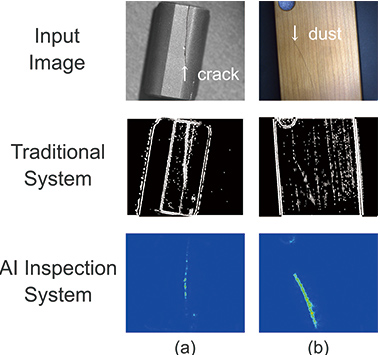
結果表明,盡管本文提出的算法屬于預學習類型,但它具有響應學習圖像中不存在的未知模式的能力。
7.結論
在本文中,我們提出了一種預訓練類型的缺陷檢測算法,該算法可以處理各種對象和缺陷類型。通過提出的方法,我們驗證了該算法還可以處理未知模式的對象和缺陷。
對于未來的前景,我們正在研究將其與更復雜的技術結合使用,以進行輸入(照明,成像),機器人的驅動技術以及在線和其他學習,以處理具有更復雜設計的對象。





